Tổng quan
RAG là gì ?
RAG - Retrieval augmented generation là một mô hình kết hợp giữa hai kỹ thuật là retrieval (truy xuất thông tin) và generation (tạo sinh văn bản). Trong mô hình RAG, khi gặp một truy vấn, hệ thống sẽ đưa ra câu trả lời dựa trên sự kết hợp của cả thông tin được huấn luyện trước của mô hình và cả dữ liệu liên qua được lưu trữ bên ngoài mô hình để đưa ra thông tin có độ chính xác và tính cập nhật cao hơn.
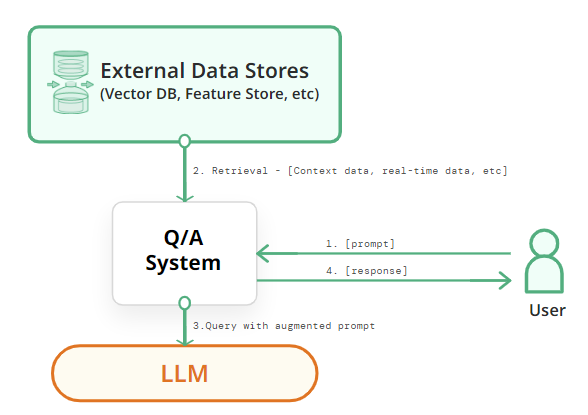
Ta có thể chia nhỏ RAG thành các bước gồm:
- Truy xuất (Retrieval) - Tìm kiếm thông tin liên quan đến đầu vào truy vấn từ một tập hợp văn bản hay cơ sở dữ liệu bên ngoài.
- Tăng cường (Augmented) - Sử dụng thông tin tìm kiếm được ở phía trên để sửa đổi/cải thiện đầu vào cho mô hình sinh (LLM,...).
- Tạo sinh (Generation) - Tạo ra đầu ra của mô hình từ thông tin truy xuất được trong dữ liệu ngoài và kiến thức nội tại của mô hình.
Tại sao lại là RAG ?
Mục tiêu chính cả RAG là cải thiện đầu ra của các mô hình LLM, trong đó, hai cải tiến chính bao gôm:
- Ngăn ngừa hiện tượng "ảo giác" (hallucination): Mặc dù trông có vẻ rất đúng và hợp lý, nhưng các mô hình LLM có thể tạo ra các thông tin sai lệch với đáp án thực, điều này có thể do dữ liệu huấn luyện chưa đầy đủ, hoặc lôi thời. RAG có thể giúp LLMs tránh được điều đó bằng cách cung cấp các thông tin sạch hơn và có thể truy gốc khi người dùng cần.
- Làm việc với dữ liệu tùy chỉnh: RAG cho phép các mô hình ngôn ngữ lớn - LLM truy cập và sử dụng dữ liệu chuyên ngành có độ chi tiết cao hơn, chuyên biệt hơn (những dữ liệu mà các nhà huấn luyện mô hình ngôn ngữ lớn không có quyền truy cập) như các hồ sơ y tế, tài liệu pháp ý, tài liệu kỹ thuật của dự án,... từ đó có thể lấy thông tin phù hợp với ngữ cảnh cụ thể của câu hỏi hoặc truy vấn (chi tiết hơn).
Có thể làm gì với RAG ?
Mục tiêu của RAG là tăng cường đầu ra cho các mô hình ngôn ngữ lớn LLM, có thể nói, RAG giúp bạn thực hiện được tất cả các chức năng của LLM với lượng dữ liệu nhiều & chính xác hơn. Ví dụ, mô hình có thể trả lời ch bạn những dữ liệu không thể truy cập công khai trên mạng.
Dưới đây là một số ví dụ điển hình về ứng dụng của RAG:
- Hỗ trợ khách hàng qua chat: RAG có thể biến tài liệu hỗ trợ khách hàng hiện có thành nguồn tài nguyên để hệ thống truy xuất thông tin khi khách hàng đặt câu hỏi. Ví dụ, Klarna, một công ty tài chính lớn, sử dụng hệ thống tương tự để tiết kiệm 40 triệu USD mỗi năm cho chi phí hỗ trợ khách hàng.
- Phân tích chuỗi email: Trong các công ty bảo hiểm, RAG có thể truy xuất các đoạn email liên quan từ chuỗi email dài giữa khách hàng và nhân viên bảo hiểm, sau đó giúp LLM tạo ra các đầu ra có cấu trúc về các yêu cầu bảo hiểm, giúp tiết kiệm thời gian tìm kiếm.
- Hệ thống chat với tài liệu nội bộ: Trong các công ty lớn, RAG có thể lập chỉ mục tài liệu nội bộ và trả lời các câu hỏi dựa trên dữ liệu công ty, đồng thời cung cấp nguồn tham khảo khi câu trả lời của LLM chưa đủ rõ ràng.
- Hỏi đáp với sách giáo khoa: Sinh viên có thể sử dụng RAG để trả lời câu hỏi từ sách giáo khoa, đồng thời cung cấp các nguồn tham khảo giúp họ hiểu sâu hơn về nội dung.
RAG khác với Fine-Tuning
RAG và Fine-Tuning là khai khái niệm khác nhau, dưới đây là so sánh nhanh giữa chúng.
- Cách hoạt động
- RAG: Kết hợp giữa việc truy xuất thông tin từ các nguồn bên ngoài và tạo ra văn bản dựa trên thông tin truy xuất được cùng với kiến thức nội tại của mô hình. Khi có truy vấn, RAG tìm kiếm dữ liệu từ cơ sở dữ liệu hoặc tài liệu cụ thể trong kho dữ liệu mà nó có thể truy cập, sau đó LLM sẽ sử dụng các thông tin này để tạo ra câu trả lời phù hợp.
- Fine-Tuning: Là quá trình tùy chỉnh mô hình bằng cách tiếp tục huán luyện mô hình cũ trên một tậ dữ liệu mới và cụ thể hơn. Mô hình sẽ học thêm từ dữ liệu này và điều chỉnh các tham số trong mô hình để cải thiện đàu ra cho những trường hợp cụ thể mà nó được tinh chỉnh.
- Mục tiêu
- RAG: Tập trung vào việc sử dụng thông tin mới và bên ngoài để cải thiện độ chính xác và tính cập nhật của câu trả lời mà không thay đổi kiến trúc nội tại của mô hình LLM.
- Fine-Tuning: Mục tiêu là cập nhật hoặc tùy chỉnh mô hình với những kiến thức mới hoặc đặc thù bằng cách điều chỉnh trực tiếp mô hình thông qua huấn luyện lại.
- Hiệu quả và thời gian triển khai:
- RAG: Có thể triển khai nhanh chóng vì không yêu cầu huấn luyện lại mô hình, chỉ cần cập nhật hoặc thêm các nguồn thông tin là mô hình có thể hoạt động hiệu quả với dữ liệu mới.
- Fine-Tuning: Đòi hỏi quá trình huấn luyện mất nhiều thời gian, tài nguyên tính toán và cần có một tập dữ liệu lớn và chất lượng.
- Kiểm soát và truy ngược:
- RAG: Cho phép người dùng xem và kiểm tra các nguồn tài liệu mà mô hình truy xuất, giúp tăng tính minh bạch và khả năng giải thích của các câu trả lời.
- Fine-Tuning: Sau khi mô hình được tinh chỉnh, các câu trả lời được tạo ra chủ yếu dựa vào kiến hức mà mô hình học được, nhưng không thể truy xuất được ngườn gốc cụ thể như RAG.
Các thuật ngữ cần quan tâm
| Thuật ngữ | Mô tả |
|---|---|
| Token | Là những phần nhỏ nhất của một đoạn văn bản, nó thể thể là từ, một phần của từ, dấu câu. Ví dụ, đoạn văn bản "Hello, world!" sẽ được chia thành các token ["Hello"; ","; "world"; "!"]. |
| Embedding | Một cách biểu diễn dữ liệu dưới dạng số, ví dụ như một đoạn văn bản có thể chuyển thành 1 chuỗi số (vector). Những dữ liệu (câu/đoạn/nội dung) tương tự thường có vector gần giống nhau. |
| Embedding model | Mô hình này chuyển các văn bản hoặc dữ liệu thành vector số, giúp máy tính hiểu được nội duGiới hạnng văn bản. |
| Similarity search/vector search | Kỹ thuật tìm ra những dữ liệu có sự liên quan bằng cách so sánh các vector. Hai văn bản có sự tương tự sẽ có các vector gần nhau trong không gian đa chiều (thường được đo bằng tích vô hướng hoặc cosine similarity). |
| Large language model (LLM) | Các mô hình được huấn luyện trên lượng văn bản lớn để "hiểu" và tạo ra các văn bản mới. LLM có khả năng tiếp tục chuỗi văn bản dựa trên đoạn văn bản đã cho, ví dụ mô hình có thể hoàn thành câu dựa trên phần đầu. |
| LLM context window | Giới hạn số lượng token mà mô hình có thể xử lý cùng một lúc. Cửa sổ ngữ cảnh (LLM context window) lớn cho phép mô hình sử dụng nhiều thông tin hơn dể tạo ra các kết qủa chính xác hơn. |
| Prompt | Là đầu vào được thiết kế để cung cấp cho mô hình ngôn ngữ (là nhưng gì bạn nói với mô hình để nó hiểu bạn đang cần gì). Ví dụ: "Hôm nay thời tiết thế nào?"; "Viết một đoạn văn về cách hoạt động của xe điện." |